Rows: 115668 Columns: 16
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): Data As Of, Start Date, End Date, Group, State, Sex, Age Group, Foo...
dbl (8): Year, Month, COVID-19 Deaths, Total Deaths, Pneumonia Deaths, Pneum...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Data Contents
str(Raw_Data)
spc_tbl_ [115,668 × 16] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ Data As Of : chr [1:115668] "01/25/2023" "01/25/2023" "01/25/2023" "01/25/2023" ...
$ Start Date : chr [1:115668] "01/01/2020" "01/01/2020" "01/01/2020" "01/01/2020" ...
$ End Date : chr [1:115668] "01/21/2023" "01/21/2023" "01/21/2023" "01/21/2023" ...
$ Group : chr [1:115668] "By Total" "By Total" "By Total" "By Total" ...
$ Year : num [1:115668] NA NA NA NA NA NA NA NA NA NA ...
$ Month : num [1:115668] NA NA NA NA NA NA NA NA NA NA ...
$ State : chr [1:115668] "United States" "United States" "United States" "United States" ...
$ Sex : chr [1:115668] "All Sexes" "All Sexes" "All Sexes" "All Sexes" ...
$ Age Group : chr [1:115668] "All Ages" "Under 1 year" "0-17 years" "1-4 years" ...
$ COVID-19 Deaths : num [1:115668] 1098594 413 1446 227 444 ...
$ Total Deaths : num [1:115668] 10215767 59245 105422 11382 17721 ...
$ Pneumonia Deaths : num [1:115668] 1036445 798 2258 496 643 ...
$ Pneumonia and COVID-19 Deaths : num [1:115668] 551596 68 367 54 129 ...
$ Influenza Deaths : num [1:115668] 19209 49 367 116 165 ...
$ Pneumonia, Influenza, or COVID-19 Deaths: num [1:115668] 1600437 1190 3688 780 1115 ...
$ Footnote : chr [1:115668] NA NA NA NA ...
- attr(*, "spec")=
.. cols(
.. `Data As Of` = col_character(),
.. `Start Date` = col_character(),
.. `End Date` = col_character(),
.. Group = col_character(),
.. Year = col_double(),
.. Month = col_double(),
.. State = col_character(),
.. Sex = col_character(),
.. `Age Group` = col_character(),
.. `COVID-19 Deaths` = col_double(),
.. `Total Deaths` = col_double(),
.. `Pneumonia Deaths` = col_double(),
.. `Pneumonia and COVID-19 Deaths` = col_double(),
.. `Influenza Deaths` = col_double(),
.. `Pneumonia, Influenza, or COVID-19 Deaths` = col_double(),
.. Footnote = col_character()
.. )
- attr(*, "problems")=<externalptr>
Cleaning Data of interest
Remove special characters from column names
# Save copy of the raw data to cleandata = Raw_Data#remove special charactersnames(data) =gsub(" ", "_",gsub("-", "_",gsub(",", "", names(data))))
Change data types where necessary.
character -> date
numeric -> character
data = data %>%mutate_at(vars('Data_As_Of', 'Start_Date','End_Date'), as_date,format ="%m-%d-%y" )%>%mutate(Year =as.character(Year))
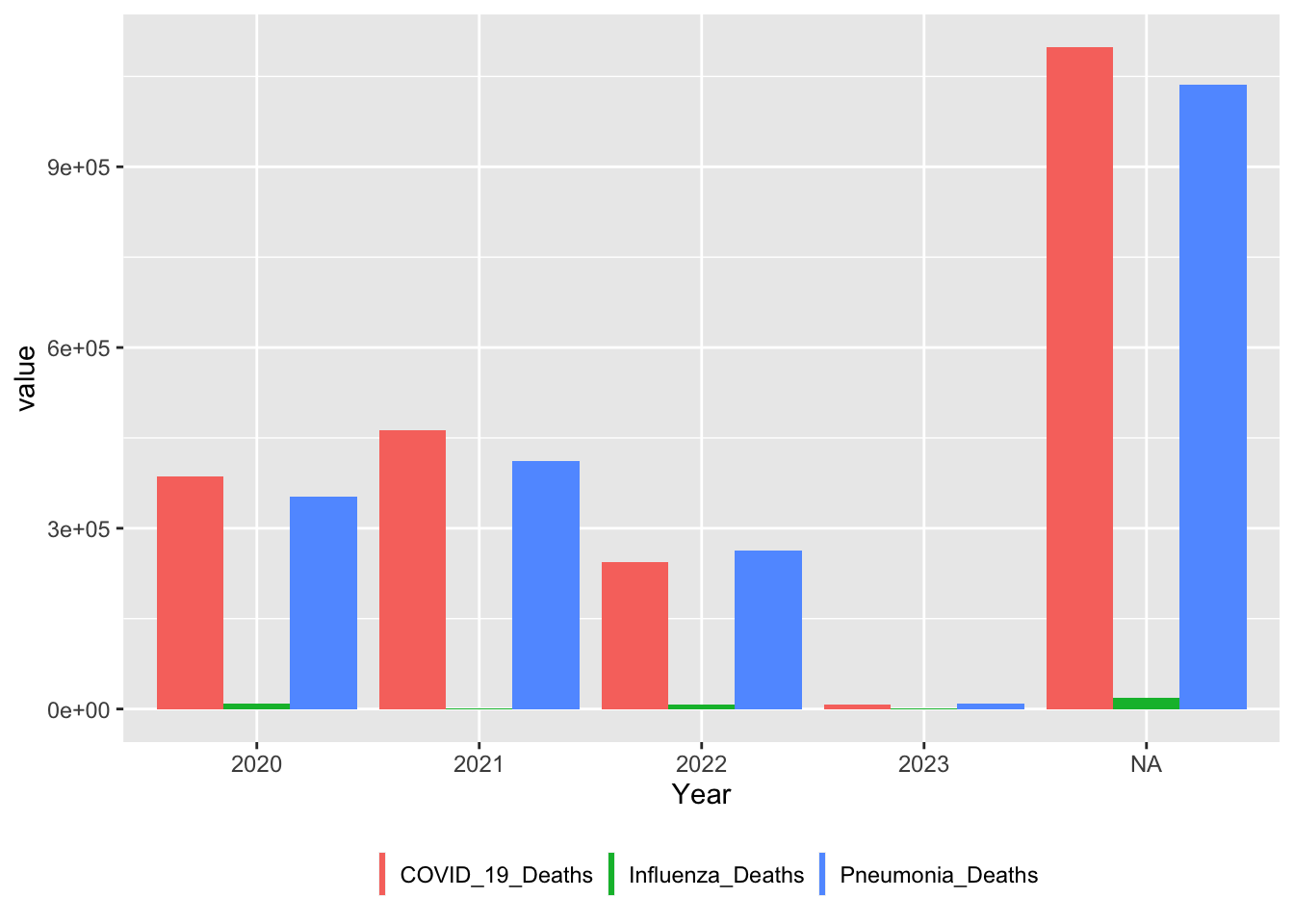
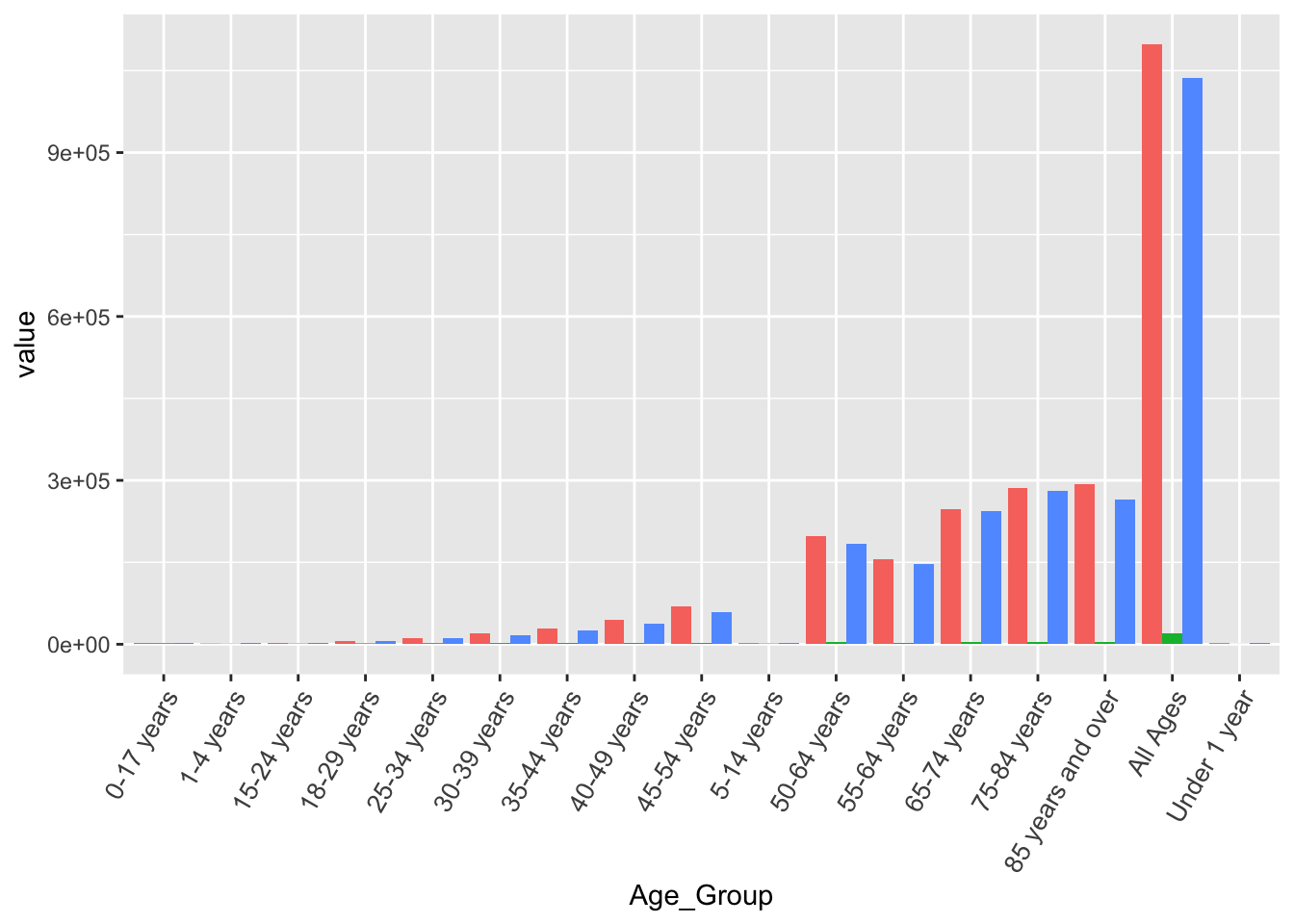
According to the footnotes column, there are multiple data points that had been suppressed due to NCHS confidentiality standards. Separated by state and/or age have many points that have been suppressed. The best option is to subset the data by year, and keep only rows containing all ages, and states.
Subset to keep
collected in 2020 and 2021
clean_data = data %>%filter(State =="United States",Age_Group=="All Ages",Year ==2020| Year ==2021, Sex =="All Sexes")%>%select(Start_Date, End_Date, COVID_19_Deaths,Pneumonia_Deaths,Influenza_Deaths, Group, Sex, Year)
clean_data
# A tibble: 26 × 8
Start_Date End_Date COVID_19_Deaths Pneumonia_D…¹ Influ…² Group Sex Year
<date> <date> <dbl> <dbl> <dbl> <chr> <chr> <chr>
1 2020-01-01 2020-12-31 385666 352010 8787 By Y… All … 2020
2 2021-01-01 2021-12-31 463199 412020 1092 By Y… All … 2021
3 2020-01-01 2020-01-31 6 17909 2125 By M… All … 2020
4 2020-02-01 2020-02-29 25 15740 2373 By M… All … 2020
5 2020-03-01 2020-03-31 7174 22479 2437 By M… All … 2020
6 2020-04-01 2020-04-30 65550 46427 1237 By M… All … 2020
7 2020-05-01 2020-05-31 38329 29010 126 By M… All … 2020
8 2020-06-01 2020-06-30 18026 19294 40 By M… All … 2020
9 2020-07-01 2020-07-31 31135 27121 50 By M… All … 2020
10 2020-08-01 2020-08-31 29911 27358 43 By M… All … 2020
# … with 16 more rows, and abbreviated variable names ¹Pneumonia_Deaths,
# ²Influenza_Deaths
Save Data and Summary
str_data =str(clean_data)
tibble [26 × 8] (S3: tbl_df/tbl/data.frame)
$ Start_Date : Date[1:26], format: "2020-01-01" "2021-01-01" ...
$ End_Date : Date[1:26], format: "2020-12-31" "2021-12-31" ...
$ COVID_19_Deaths : num [1:26] 385666 463199 6 25 7174 ...
$ Pneumonia_Deaths: num [1:26] 352010 412020 17909 15740 22479 ...
$ Influenza_Deaths: num [1:26] 8787 1092 2125 2373 2437 ...
$ Group : chr [1:26] "By Year" "By Year" "By Month" "By Month" ...
$ Sex : chr [1:26] "All Sexes" "All Sexes" "All Sexes" "All Sexes" ...
$ Year : chr [1:26] "2020" "2021" "2020" "2020" ...
summary_data =summary(clean_data)summary_data
Start_Date End_Date COVID_19_Deaths Pneumonia_Deaths
Min. :2020-01-01 Min. :2020-01-31 Min. : 6 Min. : 15624
1st Qu.:2020-06-08 1st Qu.:2020-08-07 1st Qu.: 18220 1st Qu.: 21174
Median :2020-12-16 Median :2021-01-15 Median : 31732 Median : 28184
Mean :2020-12-03 Mean :2021-01-27 Mean : 65297 Mean : 58772
3rd Qu.:2021-05-24 3rd Qu.:2021-07-23 3rd Qu.: 52139 3rd Qu.: 41722
Max. :2021-12-01 Max. :2021-12-31 Max. :463199 Max. :412020
Influenza_Deaths Group Sex Year
Min. : 28.00 Length:26 Length:26 Length:26
1st Qu.: 47.75 Class :character Class :character Class :character
Median : 81.50 Mode :character Mode :character Mode :character
Mean : 759.92
3rd Qu.: 303.75
Max. :8787.00
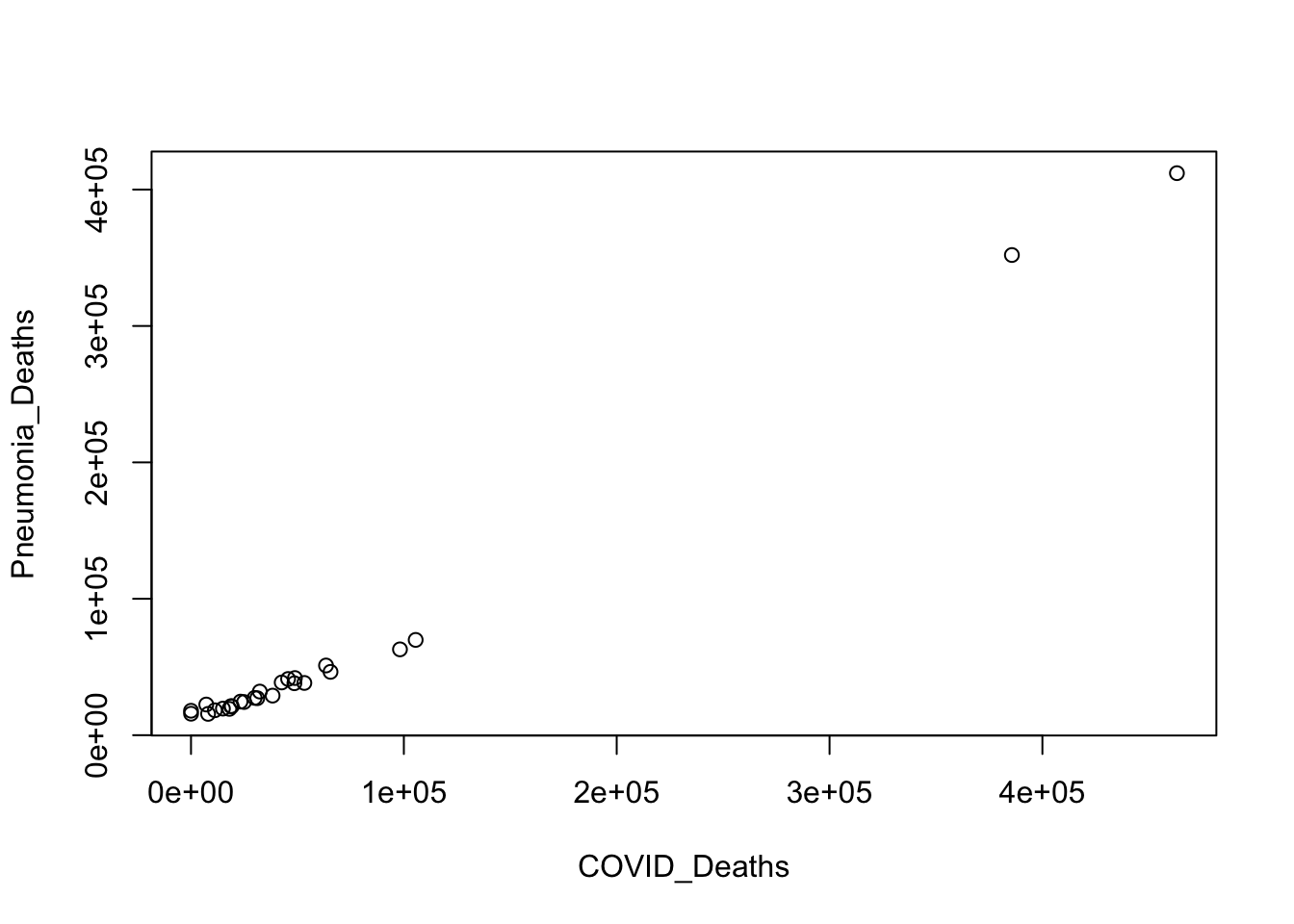
It appears there a really strong postive correlation between Covid 19 deaths and pneumonia death. Lets calculate the correlation coefficient to see if it agrees with the scatter plot above.
cor(COVID_Deaths, Pneumonia_Deaths)
[1] 0.9944441
Given the correlation coefficient of 0.99 we can say that covid-19 deaths and pneumonia deaths have a strong postive correlation.